The LLM code bet
Companies and projects are using new LLM tools to do coding tasks. These are some thoughts on the changes so far and the bet that it constitutes.
The pre LLM way
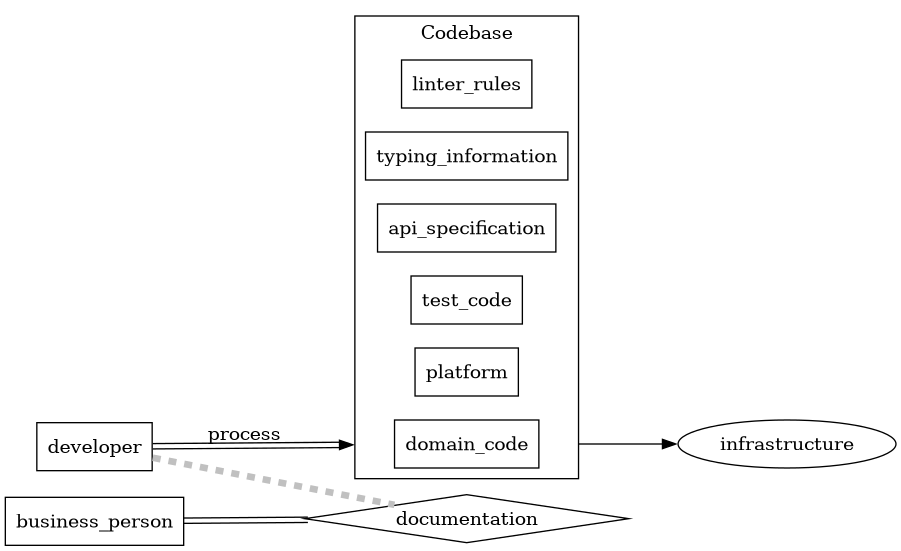
Somebody has an idea and decides to either implement or hire someone to do it.
There is a tiny loop in here where the business knowledge slowly accumulates in the codebase as the code is written. I will refer to this as domain wealth .
Two sections in here do most of the heavy lifting:
- documentation: Any written form of the business knowledge or processes
- process: The ways people adopt to produce the desired outcome.
Poor documentation, process or implementation leads to tech debt as the codebase drifts away from the actual business. Most of the code belongs to platform, testing, libraries and has no direct business relationship.
The post LLM way
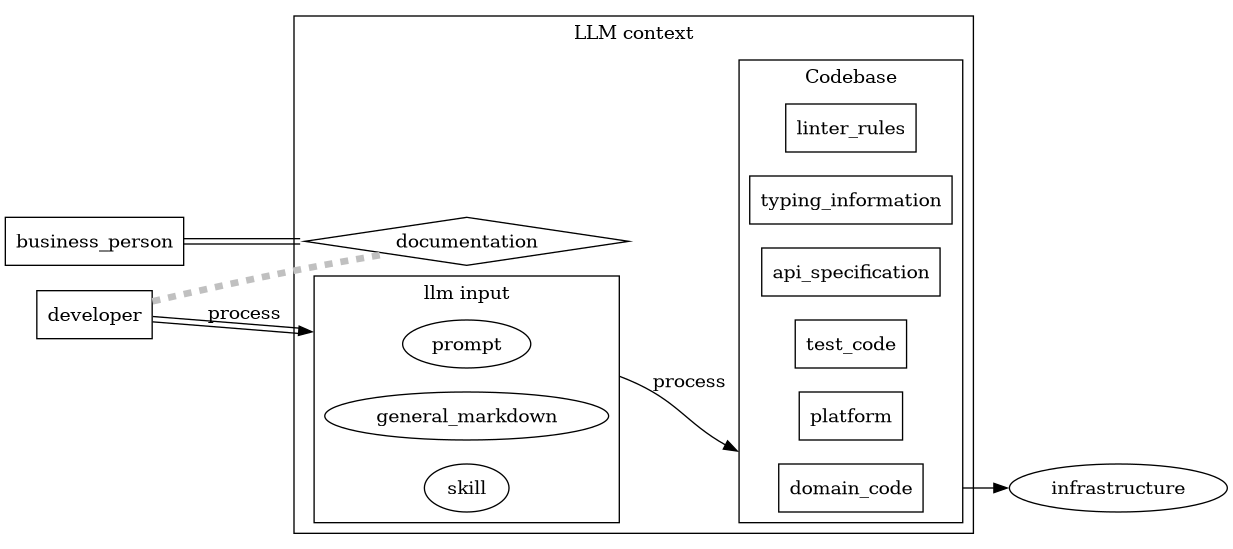
Now they use a LLM combined and prompts to produce the codebase. The current LLM services allow to provide markdown files as a way to persist the prompts. MCP is also an option to persist interfaces.
There is a tiny loop in here where the business knowledge slowly accumulates in the markdown files that have not been produced nor ever modified by the LLM.
The same two sections apply, but the process and the documentation can contain LLM outputs.
Aside from the tech debt, cognitive debt can also accrue as there is no need to fully understand the business requirements to produce the desired outcome.
The bet
Some projects believe that the increase of productivity (1) is greater than:
- the cost of the added debt (2),
- the change of developer costs (3)
- the changes in procedures (4)
- the LLM service (5)
- the long term loss of domain wealth in code (6).
(1) I don’t think there is enough evidence to measure the changes of productivity.
(2) The added debt is also hard to measure. There are reports of teams hitting a wall of cognitive debt but like productivity it is hard to know with the current data.
(3) The changes of LLM costs is also difficult to predict. Most people report that LLMs are as useful as the knowledge and skill of the prompter. So will salaries increase for those that already have the knowledge and are willing to use LLMs. However most people that are not skilled or experienced will find harder to find jobs.
(4) The changes of procedures are unknown. Things like code reviewing, merge (pull) requests, code ideation, code design, testing strategies all have to change. Given that LLMs work in the negative space of adding restriction of what is generated, there will be a shift to restrictions compared to the traditional implementation process.
Agents can act autonomously or semiautonomously, adding further complication and imprecision to the procedures.
I believe that the tools are not quite ready for this shift. Typing systems, tests methodologies and software paradigms are not made for this level of imprecision. Ultimately this will contribute to (6)
(5) The cost of LLMs are a serious concern. The route for profitability is not clear. Models require big companies with capital investment available and hardware out of reach for most people (thank you). I have been using the heuristic of revenue/capex to conclude that the real price with consolidated players or monopolies is at least 5x the current price.
Even if the current cost is stable, this cost will continue as a rent forever while the codebase needs changes. This cost will be added to the existing infrastructure costs.
(6) Loss of domain wealth is similar to (2) and there is no easy way to measure it. This depends on both if the markdown description can contain domain information with enough detail and if domain implementation is a requirement to the project.
An added concern is how difficult will be to climb down from a high LLM project to a more traditional project. The procedures will need to change, and (2) and (6) will guarantee a painful transition that will make (5) hard to escape.