Exploring LLMs from a DSL perspective
Long time ago I wrote pydsl thinking that DSLs would, if easy enough to make and use, be equivalent to programming languages.
This turned out to be mostly wrong, as programming languages remain the most common way to tackle business problems. Ian Cooper wrote about different generations of programming languages and accidental complexity of DSLs
https://ian-cooper.writeas.com/is-ai-a-silver-bullet
I wanted to explore the transformer architecture and compare it to DSLs.
The DSL/parser architecture
The way I thought about it is that tiny reusable languages could be composed easily:

Where each language would accept certain types of inputs, have their own tokens and produce outputs. The difficulty is to write these parsers easily and all the error handling that would come with it.
The Transformer architecture
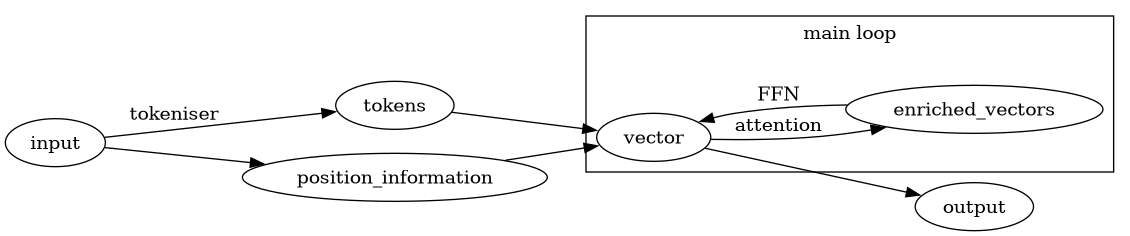
This is my current understanding of the transformer architecture for a decoder only: (read from https://dev.to/pranaybathini/the-transformer-architecture-a-deep-dive-into-how-llms-actually-work-4c46)
step1
- tokenisation: Where token is some stem, prefixes and suffixes combination
- embedding: rather than individual symbols, tokens are vectors of hundreds or thousands of dimensions vector width Number of parameters: a lot of it comes from embedding layer
step2
Position information: A new vector vector width per position that combines with the embedding. It says sine and cosine wave so maybe some FFT,,
step3
Attention: the model has somewhere between 8 and 128 attention heads. They mean grammar or meaning or similar relationships , each one do the following:
For each (word? token?) it has a
- query: what am I looking for
- key: what do I contain (? the vector)
- value: information it carries
all vector width. query and key multiply to produce a score for a pair of (word? token?)
This becomes the new value (?). All of these attention heads combine and feed into step4
step4
Thinking: Feed forward network FFN. With all the outputs of step3 it creates an enriched vector with all the attention heads. There is a bigger size vector going on and it gets compressed again.
Comparing both approaches
Compared with the LLM transformer architecture, DSLs:
- have a small number of tokens
- tokens are an entity as in individual unique thing, not a vector
- The attention step is similar to context dependent grammars, but the context is built in the grammar rules
- The FFN is the production part of the parsing as in creation of the intermediate representation or whatever output of the compiling is. The compiler production rules are equivalent to the expansion that happens in this step
- There is no loop nor layers. In transformers 3 and 4 repeat many times
- there is the possibility of “generative” aspects in the DSL, like enumerating all the possible accepted inputs https://codeberg.org/nesaro/pydsl/src/branch/master/pydsl/grammar/definition.py#L29
Overall, the ability to automate both the tokenisation and the parsing to produce a plausible outcome opens the door to a lot of automation, with the trade off of lack of certainty and massive resource consumptions.
I imagine designing a calculator as an efficiency achievement, whereas this is more like a plausible generator of output. An automation achievement